Scaling a cloud operation requires a great deal of design choices, engineering practices, and picking the right set of technologies. Critical to being competitive while scaling is also being cost-efficient. Specially for complex cloud based offerings, infrastructure costs can represent a significant part of the company expenses. At Chaordic, we achieved a factor of 3 of improvement in cost efficiency metrics in the last two years, and this post describes some of the techniques we employed to succeed.
To begin, being able to actually know your costs is the basis for intelligent decision making. While this is somewhat obvious, the ability to breakdown your costs by services and modules is of paramount importance to understand bottlenecks, spikes, trends, variable, and fixed costs. In our case, a first analysis showed that the most expensive resource in the platform was the distributed database operation. In this phase, you can make use of your cloud provider’s (in our case, Amazon Web Services) ability to tag most of the resources and report based on this. We tagged our machines according to their roles, teams, environments and some other aspects to deepen our analysis.
AWS provides many options to help you reducing costs. The trade-offs to reduce costs while keeping quality of service must be well understood. For example, once we were confident in an specific type of instance for Cassandra, we chose to commit to one year reserved instances contracts. This decision produced yearly economies from 56% to 77%, a significant reduction suitable for long- or always-running services. For short-running or non-critical tasks, you can rely on Spot instances to reduce even further machine-hour costs. The trade-off here is that this kind of instances may be shut down at any time by AWS. We have developed a Python agent - Uncle Scrooge - to manage spot usage with load balancers and compensate the absence of spots with on-demand ones. This way we could combine the quality of service of on-demand instances and the low cost of spots.
|
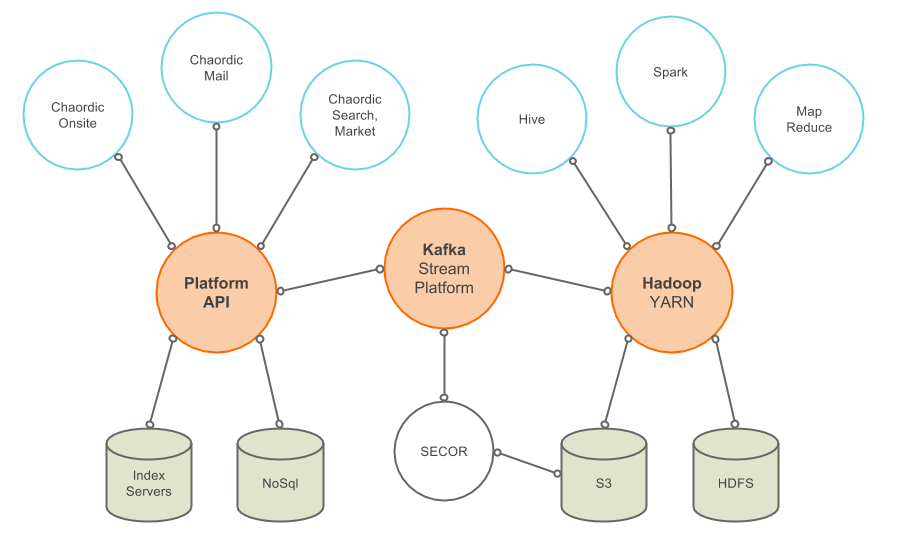
Architecture and design decisions also play a key role in cost optimization. In our case, we have decided to go even further in reducing database costs by employing data archiving based on usage patterns. AWS provides very cheap and reliable data store through S3, so instead of keeping infrequently accessed data in the more expensive database instances, we chose to archive them periodically in S3. Moreover, we decided even to completely bypass the database by employing a reliable data archive solution based on Kafka and Secor. This provided us a new 30-40% cost reduction in data storage. If you want to go a little further, moving data from S3 to Glacier, gives you another significant cost saving step. In this case, the downside is that you need to wait a few hours to recover your data.
While you can rely on external tools to help you managing your costs (see Cloudability, AWS provides basic reports, detailed CSVs of resource usage, and a tool to estimate your costs and help you making design decisions - Simple Monthly Calculator. You should also look for community tools that help you evaluating resource usage - like check-reserved-instances or the more advanced Netflix Ice.
Periodically reviewing service providers also proves to be worthy. For instance in performance monitoring, although New Relic offered us a great service, the pricing plans did not fit to our needs as we grew. So, we moved to the fast pacing DripStat, which provides a more flexible billing model, achieving almost 10x in cost savings.
We highlighted here some alternatives to reduce costs in the cloud and we hope to have inspired you to look at these opportunities. In AWS, we encourage you to start by looking at instance reservations to quickly achieve expressive results. Apart from delivering a greater efficiency, reallocating cost savings to new investments can be a motivation to start.